How to use
Bonsai.Sleap currently implements real-time inference on four distinct SLEAP-NN networks through their corresponding Bonsai Predict operators.
flowchart TD
id1("`**IplImage**`") --> id7(Multiple Instances)
id1 --> id8(Single Instance)
id7 -- centroid --> id3("`**PredictCentroids**
Returns multiple:
*Centroid*`")
id7 -- topdown --> id4("`**PredictPoses**
Returns multiple:
*Centroid*, *Pose*`")
id7 -- multi_class_topdown_combined --> id5("`**PredictPoseIdentities**
Returns multiple:
*Centroid*, *Pose*, *Identity*`")
id8 -- single_instance --> id2("`**PredictSinglePose**
Returns single:
*Pose*`")
In order to use the Predict operators, you will need to provide the ModelFileName of the exported .onnx file containing your exported SLEAP-NN model. Make sure the export_metadata.json file is located in the same folder as the exported .onnx file.
The simplest Bonsai workflow for running the complete SLEAP-NN multi_class_topdown_combined model is:
If everything works out, your poses should start streaming through! The first frame will cold start the inference graph which may take a few seconds to initialize, especially when using GPU inference with CUDA or TensorRT for the first time.
Note
The TensorRT execution provider compiles a whole new module targeting the TensorRT engine specific for your GPU. This engine is cached by default in the .bonsai/onnx folder so subsequent runs should start much faster.
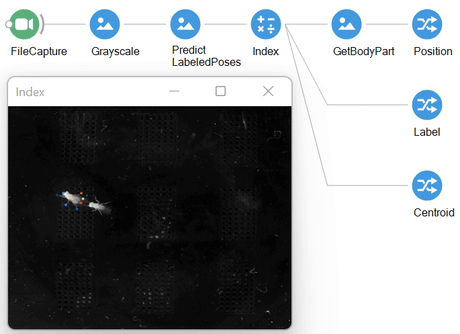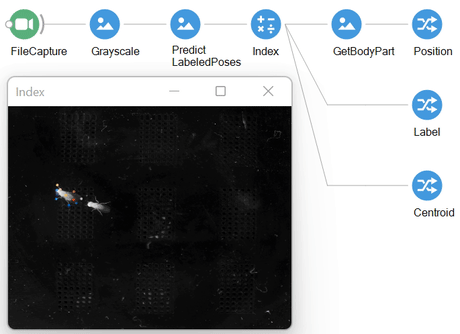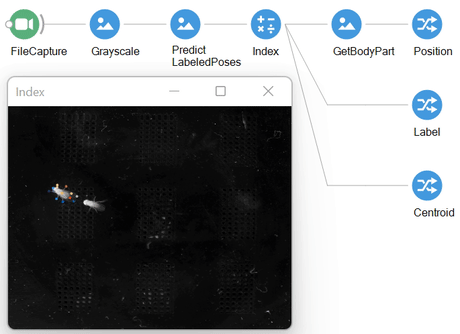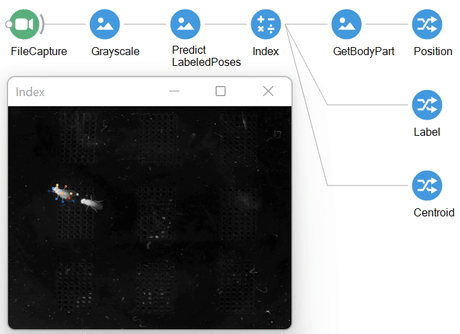
Working examples for each of these operators can be found in the extended descriptions, which we cover below.
PredictCentroids
PredictCentroids runs the centroid model. This model is most commonly used to find a set of candidate centroids from a full-resolution image. For each frame, it will return a CentroidCollection which can be further indexed to access the individual instances.
As an example application, the output of this operator is also fully compatible with the CropCenter transform node, which can be used to easily generate smaller crops centered on the detected centroid instance (i.e. Centroid)
PredictPoses
PredictPoses runs the topdown model. This model is used to find multiple instances in a full frame. This operator will output a PoseCollection object containing the collection of instances found in the image. Indexing a PoseCollection will return a Pose where we can access the Centroid for each detected instance along with the Pose containing information on all trained body parts.
The GetBodyPart operator can be used to access the data for a specific body part. By setting the Name property to match the part name defined in the export_metadata.json file, the operator will filter the collection and send notifications for the selected BodyPart object and its inferred position (BodyPart.Position).
PredictPoseIdentities
PredictPoseIdentities runs the multi_class_topdown_combined model. This model combines the centroid detection model with a centered instance multiclass model. In addition to extracting pose information for each detected instance in the image, this model also returns the inferred identity of the object.
In addition to the properties of the Pose object, the extended PoseIdentity class adds Identity property that indicates the highest confidence identity. This will match one of the class names found in export_metadata.json. The IdentityScores property indicates the confidence values for all class labels.
The operator GetMaximumConfidencePoseIdentity can be used to extract the PoseIdentity with the highest confidence from the input PoseIdentityCollection. By specifying a value in the optional Identity property, the operator will return the instance will the highest confidence for that particular class.
PredictSinglePose
PredictSinglePose runs the single_instance model. Most Bonsai.SLEAP operators support the detection of multiple instances for each incoming frame. However, there are advantages in both performance and flexibility of identifying a single object in the frame when alternative pre-processing methods for identifying cropped regions are available.
Note
Since the centroid detection step is not performed by the network, the operator expects an already centered instance on which it will run the pose estimation. This operator will always return a single output per incoming frame, even if no valid instances are detected.
The following example workflow highlights how combining basic computer-vision algorithm for image segmentation for centroid detection with SLEAP-NN pose estimation may result in >2-fold increases in performance relative to PredictPoses operator. In this example, the first part of the workflow segments and detects the centroid positions (output of BinaryRegionAnalysis) of all available objects in the incoming frame, which are then combined with the original image to generate centered crops (CropCenter). These images are then pushed through the network that will perform the pose estimation step of the process.
Finally, it is worth noting that PredictSinglePose offers two input overloads. When a sequence of single images is provided, the operator will output a corresponding sequence of Pose objects. Since the operator skips the centroid-detection stage, it won't embed a Centroid field in the returned Pose.
Alternatively, a batch mode can be accessed by providing a sequence of batches (arrays) of images to the operator. In this case, the operator returns a sequence of PoseCollection objects, one for each input frame. This latter overload can result in dramatic gains in throughput relative to processing single images.